激光快速成型制造和循环疲劳寿命预测
发布时间:2023-08-07 00:00:00 阅读数: 156
激光增材制造和激光粉末床熔融技术
激光快速成型制造(AM)技术的新进展激发了使用该技术直接生产功能部件的灵感,而不仅仅是快速成型。由于加工变量种类繁多,激光增材制造系统比传统制造方法更为复杂。例如,在激光粉末床熔融(L-PBF)工艺中,激光功率、扫描速度、层厚度和填充技术都是可编程的因素(见图 1)。这些参数的变化会产生不同的微观结构、缺陷和热行为。
由于微观结构和缺陷对断裂起始有重大影响,因此高循环疲劳是对加工极为敏感的材料质量之一。随着缺陷密度的增加,间距较近的缺陷之间的相互作用会加速断裂扩展和断裂。
随着缺陷尺寸的减小,分层微结构特征(如宏观尺度上的定向晶粒和熔池以及微观尺度上的超细亚晶粒、气孔和夹杂物)的后果也变得非常重要。
由于改变材料行为的 L-PBF 缺陷种类繁多,因此机理疲劳模型的使用进展不大。例如,在基于缺陷的构成模型中,经常假设微观结构影响较小或微观结构布局均匀。然而,众所周知,L-PBF 加工过程中的高温梯度会产生高度异构和各向异性的微观结构。由于部件与部件之间和构建与构建之间存在较大的差异,以及加工过程对微结构形成的影响,很难表征微结构特征,如晶粒和夹杂物尺寸。
由于现有模型不包括 L-PBF 相关元素,因此无法直接绘制加工过程与属性之间的联系。使用不同的模型分别处理工艺-结构和结构-属性之间的相互作用会产生较高的计算成本和各种模型来源。
例如,L-PBF 不锈钢 316L 的工艺与疲劳寿命关系可借助使用实验设计技术的数据驱动方法来探索双因素系统。然而,疲劳失效行为过于复杂,无法使用一阶或二阶回归方程进行准确描述。此外,由于系统化的实验设计无法适应文献或公共领域的数据,使用这些方法创建的模型往往具有有限的通用能力。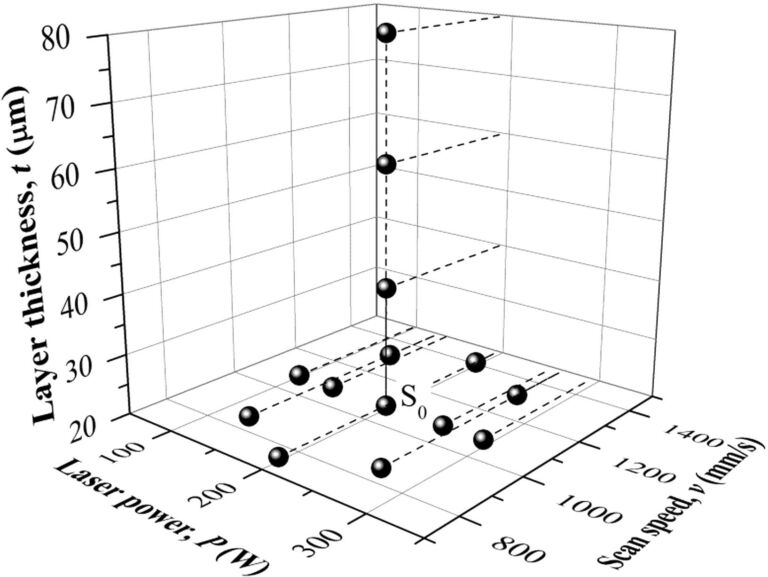
图 1:激光粉末床熔融加工条件;图片由爱思唯尔提供
在本文中,我们将讨论南洋理工大学、新加坡制造技术研究院和考文垂大学开展的一项研究。这些研究小组测试了自适应神经推理系统(ANFIS)(如图 3 所示)在考虑加工/后加工环境和循环应力的情况下预测 L-PBF 不锈钢 316L 样品高循环疲劳寿命的能力。此外,他们还使用了由 139 个实验疲劳数据组成的部分数据集来训练模型。他们创建了两个模型,将加工/后处理参数和拉伸特性作为各自的输入。通过使用模型分析测试数据,并与文献研究结果进行交叉验证,他们评估了模型的性能。
图 2:显示裂纹起始的 SEM 断裂图像;图片由 Elsevier 提供
激光快速成型制造案例的数据收集
研究人员以 L-PBF 不锈钢 316L 为例,说明了疲劳如何在概率上发挥作用。在加工 L-PBF 时,竞争性晶粒生长会导致非平衡凝固,从而在晶粒和亚晶粒边界产生第二相和位错颗粒,并形成不同取向的晶簇。
晶界处巨大的局部应力集中促进了晶间开裂(见图 2)。在裂纹起始处,密集的超细蜂窝状亚晶粒清晰可见,表明出现了晶间开裂。
如样品 3 的图 2c 和样品 8 的图 2d 所示,在这一加工区域,当输入的能量越大时,裂纹就会从晶间裂纹为主转变为晶间裂纹为主。
跨晶断裂可能是由于冷却速度较慢时扩散时间较长,第二相颗粒优先聚集在亚晶界而不是晶界。能量输入的进一步增加导致过热,合金元素的蒸发导致材料性能下降。
由于层与层之间以及轨道与轨道之间的重叠不足,随着激光能量输入的减少,产生了大量不规则的无熔合缺陷。如图 2e 所示,缺陷驱动的裂纹起因于沿缺陷尖锐边缘的强应力场。当能量输入进一步减少时,缺陷变得更大、更多。如图 2f 所示,由于间距较近的缺陷之间的相互作用放大了应力场,许多缺陷同时开始开裂。
请注意,样品 4 的裂纹起因既有微结构驱动因素(图 2a),也有缺陷驱动因素(图 2e)。两种失效模式都有可能发生,这取决于微观结构和缺陷排列,如尺寸、方向和位置,因为在此加工条件下产生的缺陷可能已接近临界尺寸,从而导致从微观结构驱动转向缺陷驱动的裂纹起始。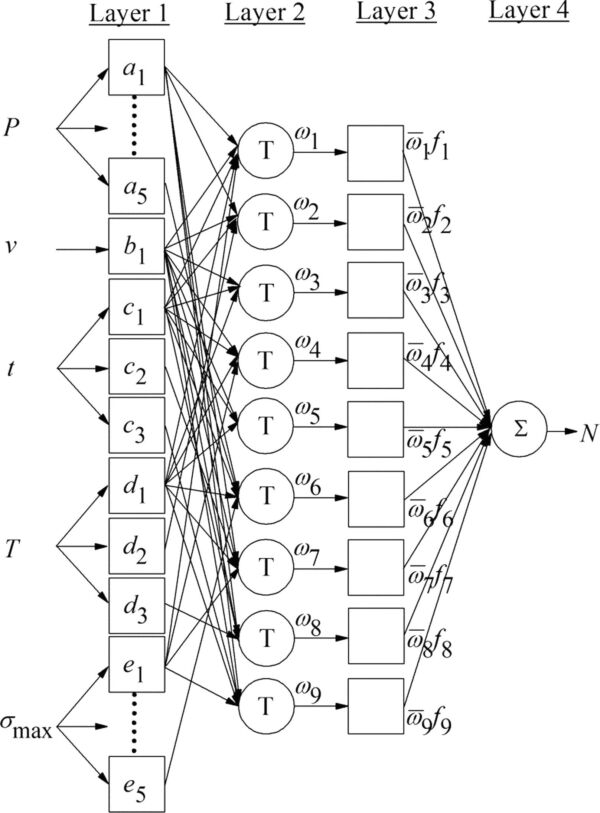
图 3:自适应神经模糊推理系统 (ANFIS) 的结构;图片由爱思唯尔提供
一些结果和启示
研究人员在工作中使用基于自适应神经模糊的机器学习技术对 L-PBF 不锈钢 316L 的高循环疲劳寿命进行了建模(图 3)。所得结果可得出以下结论:
ANFIS 技术能正确预测 L-PBF 不锈钢 316L 样品的疲劳寿命(部分预测结果见图 4),这些样品具有各种材料特性和断裂行为,这些特性和行为是在使用各种加工/后处理条件以及承受各种循环应力水平的情况下产生的。模型成功捕捉到了数据集中的常见故障模式,为预测疲劳寿命的规则奠定了基础。
由于语言规范提供的透明度,模型更容易被理解,这也使得选择模型参数和简化设计和验证过程变得更加容易。与非模糊学习策略相比,ANFIS 具有这种优势。此外,使用模糊边界可能会提高数据容差,使模型能够更有效地解释 S-N 数据中的散点。
通过选择有代表性的输入变量并建立一个可观的数据库进行训练,可以提高模型的泛化能力。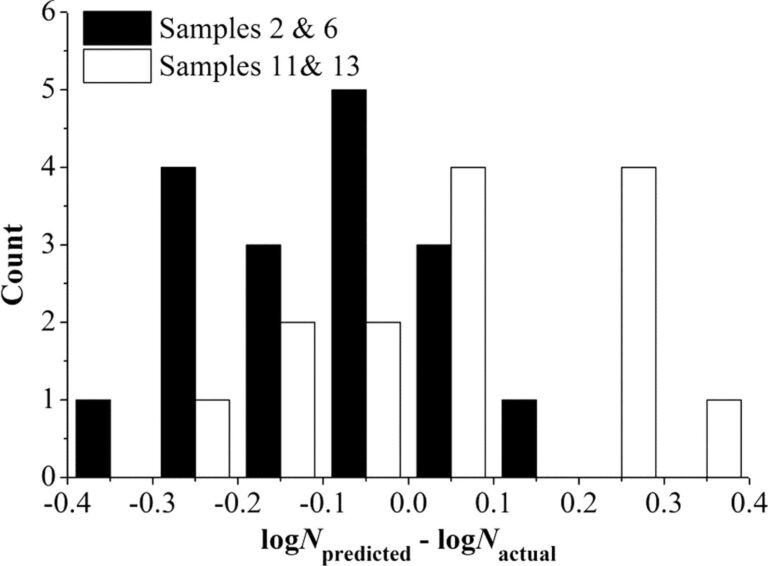
图 4:显示几个样本误差分布的直方图;图片由爱思唯尔提供