新型模拟光子强化学习法
发布时间:2023-08-23 10:20:05 阅读数: 44
东京大学的一个多学科研究小组在新川宏明(Hiroaki Shinkawa)的指导下,创建了一个扩展的光子强化学习方案,该方案从静态的强盗问题发展到更困难的动态环境。2023 年 7 月 25 日,一份名为《智能计算》的科学伙伴期刊发布了这项工作。
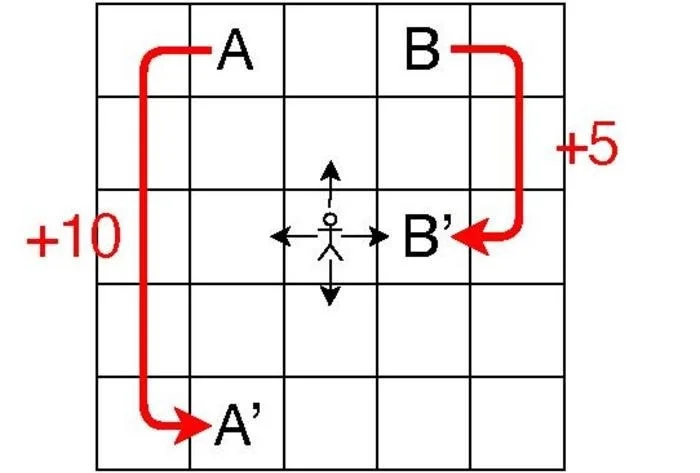
代理从黑色箭头所示的四个行动中选择一个,获得奖励并前往下一个单元。如果代理到达 A 或 B 两个特殊单元中的任何一个,奖励就会很多,代理就会跳到另一个单元,如红色箭头所示。图片来源:HIROAKI SHINKAWA ET AL.
该策略要取得成功,必须要有一个能提高学习质量的光子系统和一个辅助算法。作者创建了一种改进的强盗 Q 学习算法,并通过数值模拟测试了其效率,同时考虑了 "潜在的光子实施"。
为了加快并行学习过程,他们还评估了使用并行架构的算法,在这种架构中,许多代理同时运行。他们发现,这可以通过利用光子的量子干涉来实现,从而避免做出相互竞争的判断。
不过,作者声称,他们的工作是 "首次将光子合作决策概念与 Q-learning 联系起来,并将其应用于动态环境"。尽管在这一领域,利用光子的量子干涉并不是什么新鲜事。与强盗问题中的静态环境不同,强化学习问题通常处于动态环境中,这种环境会随着代理的活动而变化。
本研究的重点是网格环境,即一组具有不同奖励的单元格。根据其当前位置和移动情况,每个代理可以向上、向下、向左或向右移动并获得奖励。在这种情况下,代理的位置和当前移动完全决定了它下一步的走向。
本研究模拟的每个单元都使用 5×5 单元网格,每个单元被称为一个 "状态",每个代理在每个时间步采取的每个行动被称为一个 "行动",决定代理在每个状态下选择哪种行动的规则被称为一个 "策略"。
决策过程以强盗问题为模型,每个状态-行动配对就像一台老虎机,奖励是 Q 值的变化,即状态-行动配对的值。
修正的强盗 Q-learning 算法力求在整个环境中有效、正确地学习每种状态-行动组合的理想 Q 值,而基本的 Q-learning 算法通常专注于寻找最佳路径以获得最大回报。
在 "利用 "具有高值的频繁配对以加快学习速度和 "探索 "可能具有更大值的不常见配对之间,必须保持健康的平衡。该策略采用了软最大算法(softmax),这是一种擅长实现这种平衡的著名模型。
作者未来的首要目标是创建一个光子系统,促进至少三个代理之间无冲突的决策,希望在他们建议的方案中加入这样一个系统,能防止代理做出相互竞争的判断。
与此同时,他们还打算创建能让代理持续行动的算法,并将他们的强盗 Q-learning 方法用于更具挑战性的强化学习任务。
参考资料
Shinkawa, H., et al. (2023) Bandit Approach to Conflict-Free Parallel Q-Learning in View of Photonic Implementation. Intelligent Computing. doi:10.34133/icomputing.0046